Martin Bernardo Meza
Curriculum | LinkedIn | GitHub
I'm a Sound Engineering advanced student, and I have finished my final thesis work named "Speech Dereverberation using Deep Learning algorithms". Furthermore, I currently have a position as teaching fellow in Signal and Systems asignature at Universidad Nacional Tres de Febrero, where I mainly work with audio signal processes and Python programming.
I'm interested in the application of deep learning techniques to audio signal processing and analysis. More precisely, I especially like to work in applications related to speech signals.
Portfolio
Speech Dereverberation using Convolutional Neural Networks (CNN)
In this research, speech dereverberation based on deep learning algorithms is studied. A convolutional neural network model called autoencoder with skip connections is implemented, following the current state of the art. The neural network is developed to estimate amplitude masks that perform speech dereverberation in the short-time Fourier transform domain. One of the issues of this particular task is the lack of a large training dataset, so generation and augmentation techniques were analyzed, evaluating the impact on model’s performance. In addition, ways to handle phase information and data during training were studied.
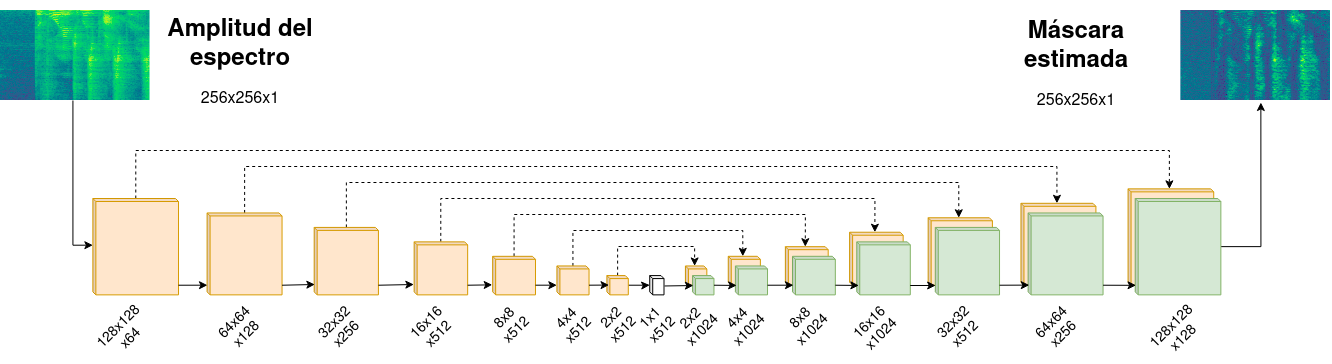
The results show that the generation and augmentation techniques allow to improve the model’s performance. Moreover, sorting the training data from smallest to largest reverberation time results in better evaluation metrics. Finally, improvements for the implemented model and future lines of research were proposed.
This research was the final thesis work developed to achieve the Sound Engineer degree in Universidad Nacional de Tres de Febrero, and has been finished in November 2021. Full document is available in this link.
Keep Reading | See GitHub Repo
Analysis and Augmentation of Room Impulse Responses
Room Impulse Response databases are usually expensive and time-consuming to collect. Moreover, if we analyze some acoustics parameters like reverberation time (RT) and direct-to-reverberant ratio (DRR) in the database, in general it is difficult to achieve a good variation of these parameters. In other words, small size datasets bring issues in some applications like training deep learning models. However, some studies have proposed several techniques to perform RIR augmentation, having control over certain acoustic parameters like the ones mentioned above, RT and DRR. Here, these techniques to parametrically control the RT and DRR where implemented generating a useful tool that allows expand a small dataset of RIR into a balanced dataset order of magnitude larger.
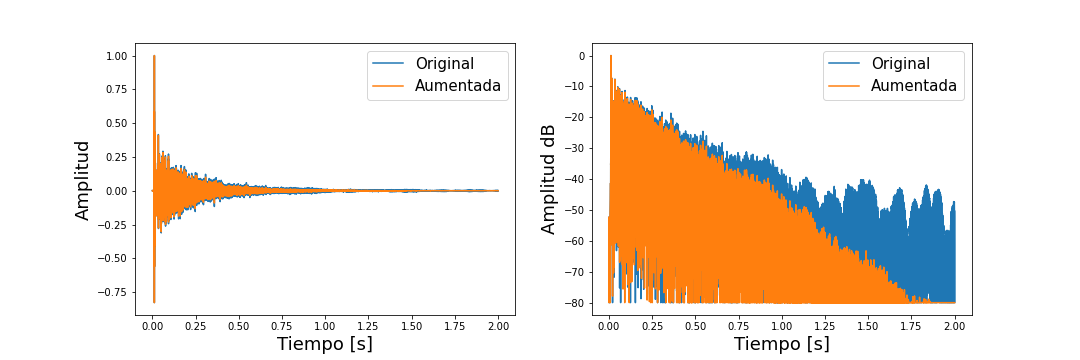
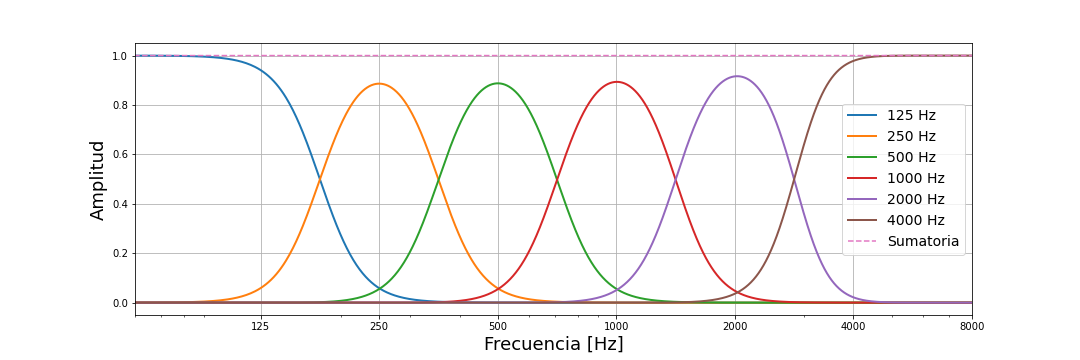
Also, this work provide some python scripts to perform basic acoustic analysis of audio signals, and more precisely, of RIRs, such as band-filtering, reverberation time calculation, direct-to-reverberant ratio calculation, and implementations of noise floor estimation methods.